IA, Données 5 min de lecture
Les LLM tabulaires sont désormais une réalité — et apportent des avancées majeures aux équipes chargées de la gestion des risques


Les progrès réalisés dans le domaine de l'apprentissage profond ont donné lieu à des avancées majeures dans presque tous les secteurs, de la mobilité (Waymo) à la biologie (AlphaFold) en passant par la musique (Suno.ai). Cependant, malgré le succès de l'apprentissage profond dans des tâches extrêmement complexes telles que les voitures autonomes, les applications liées à la gestion des risques ont été remarquablement absentes de cette révolution. Mais cela est sur le point de changer.
L'une des principales raisons pour lesquelles les équipes chargées de la gestion des risques n'ont pas encore intégré les réseaux neuronaux profonds à leur arsenal d'outils tient à leurs difficultés historiques avec les données tabulaires. Les banques, les fintechs et les compagnies d'assurance disposent d'une abondance de données tabulaires et les utilisent quotidiennement pour prévenir la fraude, détecter le blanchiment d'argent et évaluer le risque de crédit. Et lorsqu'il s'agit de construire des modèles de prédiction hautement précis pour ces cas d'utilisation, la famille des modèles d'arbres à gradient boosté a toujours régné en maître.
Le « moment ChatGPT » des données tabulaires
Lors d'un lancement que les acteurs du secteur ont qualifié de « moment ChatGPT » des données tabulaires, Prior Labs a dévoilé un modèle révolutionnaire : TabPFN. Ce modèle surpasse largement les méthodes existantes sur des ensembles de données tabulaires pour un large éventail de tâches liées aux données tabulaires — une découverte si importante qu'elle a récemment fait l'objet d'une publication dans *Nature*.
Compte tenu du large éventail d'applications à forte valeur ajoutée dans le secteur des services financiers, nous sommes ravis de nous associer à Prior Labs afin de permettre aux équipes chargées de la gestion des risques, de la lutte contre la fraude et de la conformité d'accéder à TabPFN.
Points clés à retenir
- Prior Labs a lancé un modèle révolutionnaire, TabPFN, qui surpasse largement les méthodes existantes sur des ensembles de données tabulaires, et ce pour toute une série de tâches liées aux données tabulaires.
- Ce modèle représente la nouvelle référence en matière de traitement de petites quantités de données, et les équipes n'ont pas besoin de recadrage complexe ni d'infrastructure MLOps.
- Nous nous sommes associés à Prior Labs afin de rendre TabPFN accessible sur la plateforme Taktile pour des applications dans les domaines de la gestion des risques et de l'optimisation des décisions.
- Ce modèle s'avère déjà très utile dans de nombreuses applications liées à la gestion des risques, telles que les contrôles anti-fraude et la détection d'anomalies en matière de risque de crédit.
Fonctionnement de TabPFN
Contrairement aux tentatives précédentes visant à rendre les réseaux neuronaux profonds utiles dans des contextes tabulaires, ce modèle est pré-entraîné. À l’instar des grands modèles linguistiques (LLM) modernes, qui sont pré-entraînés sur un vaste corpus de données textuelles couvrant la majeure partie de l’Internet public, TabPFN a été pré-entraîné sur un large éventail d’ensembles de données synthétiques – ce qui constitue une innovation majeure du modèle.
Lorsque vous effectuez une prédiction avec TabPFN, vous lui fournissez un certain nombre de lignes étiquetées issues de vos données, en plus des lignes non étiquetées. L'outil complète ensuite les lignes non étiquetées par des prédictions, de la même manière qu'un modèle de langage de grande envergure (LLM) utilise les exemples fournis dans une requête pour vous aider à répondre à une question.
À première vue, cela peut paraître incroyable qu’il n’y ait pas d’entraînement du modèle au sens traditionnel du terme. Les paramètres (poids) du modèle restent fixes tout au long du processus. Au lieu de cela, le modèle s’appuie sur la flexibilité et la puissance de l’architecture « Transformer » pour apprendre les schémas présents dans vos données tout en effectuant la prédiction. Le fait que cela fonctionne aussi bien a également été une surprise aux débuts de la modélisation linguistique.
L'intérêt de TabPFN pour les professionnels de la gestion des risques
Étant donné que le modèle n'est pas entraîné pour chaque nouveau cas d'utilisation et qu'il s'appuie fortement sur ses a priori issus du pré-entraînement, cela présente certains avantages clés pour les professionnels du secteur des services financiers :
- Les experts métier peuvent désormais élaborer des prévisions à partir de modèles compétitifs sans avoir besoin de plusieurs années d'expérience en science des données — ce qui permet de constituer des équipes plus petites, plus réactives et plus autonomes.
- Ce modèle donne de bons résultats dans les contextes où les données sont peu nombreuses — ce qui est particulièrement intéressant pour les applications liées à la lutte contre la fraude, au crédit et à la lutte contre le blanchiment d'argent, car de nombreuses entreprises disposent d'un nombre relativement faible de « vrais positifs ».
- Les équipes n'ont pas besoin d'une infrastructure complexe de réentraînement et de MLOps : l'absence de réentraînement vous permet de réduire au minimum les charges liées à la validation, aux tests et à la validation finale des modèles.
TabPFN propose également des fonctionnalités supplémentaires très utiles qui constituent souvent une source de difficultés dans le domaine de l'apprentissage automatique :
- Le modèle renvoie naturellement des distributions pour ses résultats, que vous pouvez utiliser dans vos décisions ultérieures.
- Le modèle gère nativement les valeurs manquantes et les valeurs aberrantes ; vous n'avez donc pas besoin de vous soucier de l'imputation ni d'autres stratégies visant à adapter les données au format attendu par votre modèle.
- Le modèle peut fournir des explications sur ses prédictions (à l'aide de ce qu'on appelle les « valeurs de Shapley »), ce qui permet d'apaiser les inquiétudes liées à l'IA de type « boîte noire ».
« Nous sommes extrêmement enthousiastes face à la capacité de TabPFN à transformer la manière dont les équipes utilisent l'apprentissage profond pour développer et optimiser des produits financiers. Les cas d'utilisation que nous observons chez Taktile ne sont en réalité qu'un avant-goût de ce qui est possible. »
Applications concrètes de TabPFN dans des cas d'utilisation liés aux risques
1. Contrôles anti-fraude
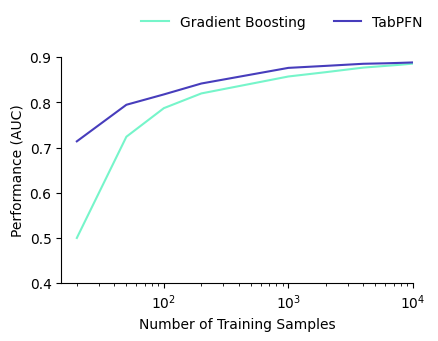
Étant donné que le modèle donne de bons résultats dans les contextes où les données sont peu nombreuses, nous pensons que son application immédiate la plus prometteuse réside dans la détection des fraudes. Nous avons évalué les performances du modèle sur un ensemble de données anonymisé et issu de la réalité, consacré à la fraude lors de l’ouverture de comptes, et nous l’avons comparé à une approche standard utilisant des arbres boostés. Plus les données sont clairsemées, plus le modèle surpasse l’approche classique d’apprentissage automatique. Notez que le modèle obtient des résultats étonnamment bons alors qu’il ne dispose pratiquement d’aucune donnée d’entraînement : c’est là toute la puissance du pré-entraînement.
Exemple : détection des fraudes lors de l'ouverture d'un compte
2. Détection des anomalies liées au risque de crédit
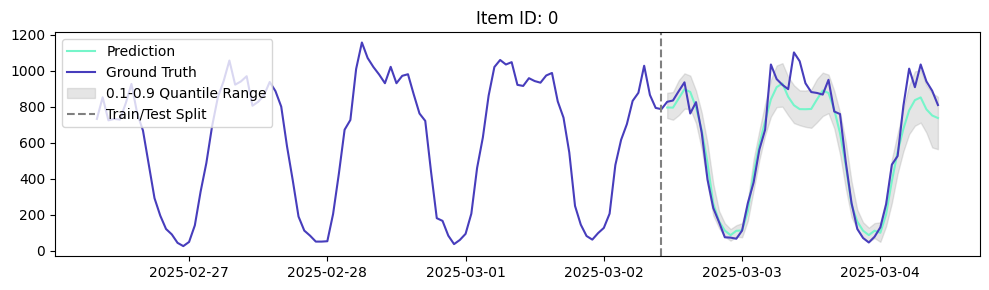
La détection d’anomalies est un autre domaine qui nous passionne. Notre modèle occupe la première place dans le domaine des séries chronologiques, surpassant même Chronos d’Amazon. Il peut donc également être utilisé pour prévoir les taux d’acceptation et des indicateurs clés, tels que le nombre de demandes ou la répartition des scores FICO des demandeurs. Si les indicateurs observés s’écartent trop de ces répartitions, vous pouvez déclencher une alerte afin que les analystes enquêtent sur l’anomalie.
Exemple : détection d'anomalies dans les demandes de prêt quotidiennes
Ce ne sont là que deux exemples qui illustrent pourquoi nous sommes si enthousiastes à propos de TabPFN : nous pensons qu’il existe d’innombrables autres cas d’utilisation intéressants.
Il reste toutefois important de tenir compte des limites. À l'heure actuelle, le temps de prédiction (latence d'inférence) est relativement élevé et la taille des données prises en charge est limitée. Nous prévoyons toutefois que ces deux contraintes s'atténueront rapidement au cours de l'année 2025.
Vous souhaitez savoir comment TabPFN pourrait apporter une valeur ajoutée à votre cas d'utilisation spécifique ?
Lectures complémentaires recommandées
- L'IA appliquée à la gestion des risques : comment les équipes chargées de la gestion des risques développent des agents IA pour avoir un impact concret
- Comment les modèles de langage de grande envergure (LLM) deviennent des partenaires d'enquête dans la détection des fraudes dans le secteur de la fintech
- De la notation de crédit à l’IA générative : comment la prise de décision en matière de crédit a évolué — et quelles sont les prochaines étapes ?
- L'IA sans le battage médiatique : tirer pleinement parti des modèles de langage à grande échelle sans se laisser distraire





