IA, fraude Temps de lecture : 5 min
Comment les modèles de langage de grande envergure (LLM) deviennent des partenaires d'enquête dans la détection des fraudes dans le secteur de la fintech


Les progrès fulgurants de l'IA ont transformé tous les secteurs d'activité, mais peu d'entre eux ont connu un impact aussi spectaculaire que celui observé dans le domaine de la gestion des risques au sein de la fintech. Les grands modèles linguistiques (LLM) sont en train de révolutionner la détection des fraudes, la conformité et l'évaluation du risque de crédit, en venant compléter les approches traditionnelles d'apprentissage automatique (ML).
Fort d’une vaste expérience à la tête de projets d’IA et de science des données dans le secteur de la fintech, je dispose d’une connaissance directe de l’intégration d’outils basés sur l’IA dans les processus décisionnels et d’automatisation. Cependant, comme nous le verrons dans cet article, les modèles de langage à grande échelle (LLM) ne sont pas des solutions miracles. S’ils permettent de mettre au jour des schémas et de rationaliser les enquêtes, leur efficacité dépend entièrement des systèmes qui les régissent. Sans une gouvernance rigoureuse et une mise en œuvre stricte, même les modèles d’IA les plus avancés, ainsi que les enquêteurs humains les plus compétents, sont impuissants.
Cet article examine la différence entre les modèles de langage de grande envergure (LLM) et l'apprentissage automatique traditionnel, leurs rôles respectifs en matière de risque de crédit, de conformité et, en particulier, de détection de la fraude — domaine que nous allons approfondir —, ainsi que l'évolution future de l'IA dans la gestion des risques.
1. La distinction traditionnelle entre l'apprentissage automatique (ML) et les modèles de langage à grande échelle (LLM) : une perspective pragmatique
Une idée reçue courante dans le secteur de la fintech est que les modèles de langage de grande envergure (LLM) sont appelés à remplacer l'apprentissage automatique traditionnel dans l'évaluation des risques. Ce n'est pas le cas.
L'apprentissage automatique reste la pierre angulaire de la modélisation du risque de crédit, car il tire pleinement parti des données structurées (principalement sous forme de tableaux) présentant des résultats clairs et binaires. Les prêteurs disposent — ou peuvent se procurer — de vastes ensembles de données historiques sur les comportements de remboursement, ce qui permet à des modèles bien calibrés, tels que CatBoost, de fournir une notation de crédit précise. Par exemple, un modèle d'apprentissage automatique traditionnel peut utiliser plus de 50 caractéristiques (par exemple, des indicateurs financiers, l'historique des paiements) pour prédire les défauts de paiement avec une grande précision.
La détection des fraudes et la conformité sont toutefois, par nature, des domaines plus ambigus. Contrairement au risque de crédit, où l’on dispose d’une « vérité de référence » sous la forme d’un historique de remboursement, la fraude B2B manque souvent de repères définitifs et d’ensembles de données structurés. C’est là que les modèles de langage grand échelle (LLM) prennent tout leur sens. Leur capacité à traiter des textes non structurés — tels que des factures, des e-mails et des articles de presse — leur permet de mettre au jour des schémas et des incohérences qui, sans cela, ne pourraient être détectés qu’à l’aide de l’intuition humaine.
Comparaison : apprentissage automatique traditionnel vs modèles de langage à grande échelle (LLM)

Exemple: un LLM a signalé une facture d’un fournisseur dans laquelle le volume d’expédition de « coton biologique » indiqué dépassait la capacité de production connue de ce dernier — un écart invisible pour les modèles d’apprentissage automatique structurés.
2. Risque de crédit : les grands modèles de langage (LLM) comme assistants (pour l'instant)
Si les modèles d'apprentissage automatique (ML) tels que CatBoost restent au cœur des décisions de crédit, les modèles de langage à grande échelle (LLM) jouent un rôle de soutien. Leur principale contribution a consisté à rationaliser les processus internes, notamment en répondant aux demandes courantes via les chatbots que nous avons créés, ce qui a permis aux équipes chargées du risque de crédit de gagner du temps.
Le financement basé sur le chiffre d'affaires a toutefois constitué une exception, les LLM s'étant particulièrement illustrés dans l'étiquetage des transactions. En classant ces dernières par catégorie (par exemple, en distinguant les « revenus d'abonnement » des « ventes ponctuelles »), ils ont amélioré la visibilité sur la trésorerie. Ces classifications ont non seulement amélioré l'analyse interne, mais ont également renforcé la précision et l'efficacité des modèles d'apprentissage automatique en aval.
Point clé: Les modèles de langage (LLM) viennent compléter — mais ne remplacent pas — l’apprentissage automatique traditionnel dans le domaine du risque de crédit. Leur rôle aujourd’hui consiste à enrichir les données d’entrée, et non à prendre des décisions finales.
3. Conformité : les modèles de langage de grande envergure (LLM) automatisent les tâches répétitives, mais pas la prise de décision
En matière de conformité transfrontalière, les modèles de langage grand échelle (LLM) ont permis de réduire de 40 % la charge de travail manuelle dans des tâches telles que les vérifications multilingues des sanctions et l’analyse des documents réglementaires. Ils ont par exemple rationalisé les processus « Know Your Business » (KYB) en signalant des incohérences dans les enregistrements d’entreprises (par exemple, une entité chinoise déclarant avoir son siège social aux États-Unis sans fournir d’adresse valide).
Toutefois, l'intervention humaine reste essentielle. Lorsqu'un modèle de langage de grande échelle (LLM) a signalé « XXX Technologies » comme une correspondance potentielle avec le « XXX Group », une entité soumise à des sanctions, les enquêteurs ont confirmé qu'il s'agissait d'un faux positif dû à des conventions de dénomination qui se recoupaient.
Point clé: Les modèles de langage (LLM) réduisent le bruit, mais ne permettent pas de s’y retrouver dans les zones d’ombre réglementaires. Une approche hybride — consistant à automatiser les premières vérifications tout en réservant le jugement humain aux cas nécessitant une intervention plus approfondie — offre le meilleur équilibre.
4. Détection des fraudes : les modèles de langage de grande envergure (LLM) changent la donne
La détection des fraudes nécessite des systèmes capables de s'adapter à l'évolution des tactiques et de mettre au jour des schémas cachés dans la complexité. Les systèmes traditionnels basés sur des règles fonctionnent bien dans des scénarios stables et prévisibles, mais s'avèrent souvent insuffisants face à des stratagèmes de fraude inédits ou sophistiqués. Les modèles de langage de grande envergure (LLM), en revanche, ont démontré une grande utilité dans les domaines où l'ambiguïté et le contexte jouent un rôle essentiel, car ils possèdent une forme de raisonnement fondé sur le « bon sens ».
L'année 2024 a marqué un tournant décisif à cet égard. Les progrès réalisés dans le domaine des modèles de raisonnement ont conduit au développement de « moteurs de raisonnement ». Popularisée par Andrew Ng, cette approche met l'accent sur l'utilisation des modèles de langage de grande envergure (LLM) pour le raisonnement sur des données ambiguës, plutôt que de s'appuyer sur eux pour obtenir des connaissances factuelles, ce qui comporte des risques d'hallucination. Inspirés par cette approche, nous avons structuré les enquêtes sur la fraude comme des tâches de résolution de problèmes fondées sur la logique.
Parallèlement, nous avons mis au point des pipelines d’OCR basés sur des modèles de langage (LLM) qui sont passés d’un état où ils étaient largement peu fiables — et ne permettaient en réalité pas de gagner de temps, car tout devait être revérifié par la suite — à des outils hautement précis pour l’extraction et la structuration des données. Dans le domaine du financement des factures, ces pipelines ont permis la numérisation automatisée des factures, des documents de transport et des contrats. En effet, nous avons pu surpasser nos anciens fournisseurs d’OCR grâce à ces avancées dans les modèles de base.
Comment les modèles de langage de grande envergure (LLM) contribuent à la détection des fraudes
Afin de renforcer les mesures de lutte contre la fraude, nous avons mis en œuvre les modèles de langage de grande envergure (LLM) de deux manières principales :
- Des outils opérationnels incontournables: ils analysent de grands volumes de factures afin de détecter les incohérences au niveau des adresses, des prix, des montants et des descriptions de produits, ce qui permet de réduire considérablement la charge de travail manuel et d'accélérer les délais de traitement.
- Moteurs de raisonnement: ces modèles agissent comme des détectives numériques, rassemblant des indices à la manière de Sherlock Holmes lors d'une enquête. Bien qu'ils en soient encore au stade expérimental, les résultats se sont révélés extrêmement prometteurs.
Une avancée notable a été réalisée dans le domaine de la mise en correspondance d’entités, un domaine dans lequel les modèles de langage de grande envergure (LLM) excellent. Notre ancien système reposait sur la correspondance approximative, une approche fragile et sensible aux différences de longueur des chaînes de caractères, aux adresses dont le format variait légèrement, etc. Par exemple, il ne parvenait pas à reconnaître que « LHR » et « London Heathrow » désignaient le même aéroport. Les LLM, en revanche, comprenaient intrinsèquement la relation entre ces entités grâce à leur vaste connaissance contextuelle issue des données d’entraînement. Cela nous a permis d’améliorer les contrôles de cohérence des données et de réduire considérablement les faux positifs.
L'impact : des gains en termes d'efficacité et de précision
Résultat ? Nous avons réduit de plus de 60 % le temps consacré à la détection manuelle des fraudes, considérablement diminué le nombre de faux positifs et amélioré la précision de la détection des anomalies. Les prochaines itérations viseront à affiner la capacité d'adaptation du système et à réduire au minimum le recours à l'intervention humaine dans les cas à faible risque.
L’un des avantages inattendus réside dans la capacité des modèles de langage de grande échelle (LLM) à détecter des incohérences subtiles qui échappaient aux systèmes traditionnels et aux analystes. Par exemple, ils ont permis de mettre au jour un réseau de fraude en identifiant des erreurs grammaticales récurrentes sur des factures émanant d’entités apparemment sans lien entre elles. Si les LLM excellent dans la détection de telles anomalies, les enquêteurs humains restent indispensables pour vérifier ces informations et en tirer les conclusions qui s’imposent.
Un enseignement clé : Évitez les consignes génériques. Les stratagèmes de fraude varient selon les secteurs d’activité et les zones géographiques, ce qui nécessite des workflows d’IA sur mesure. La meilleure approche est itérative, et les consignes doivent être affinées en fonction des faux positifs et des faux négatifs.
Assurer l'efficacité de la détection des fraudes : les enseignements tirés du terrain
Après avoir affiné notre approche en matière de détection des fraudes, nous avons mis au point un processus structuré mais flexible :
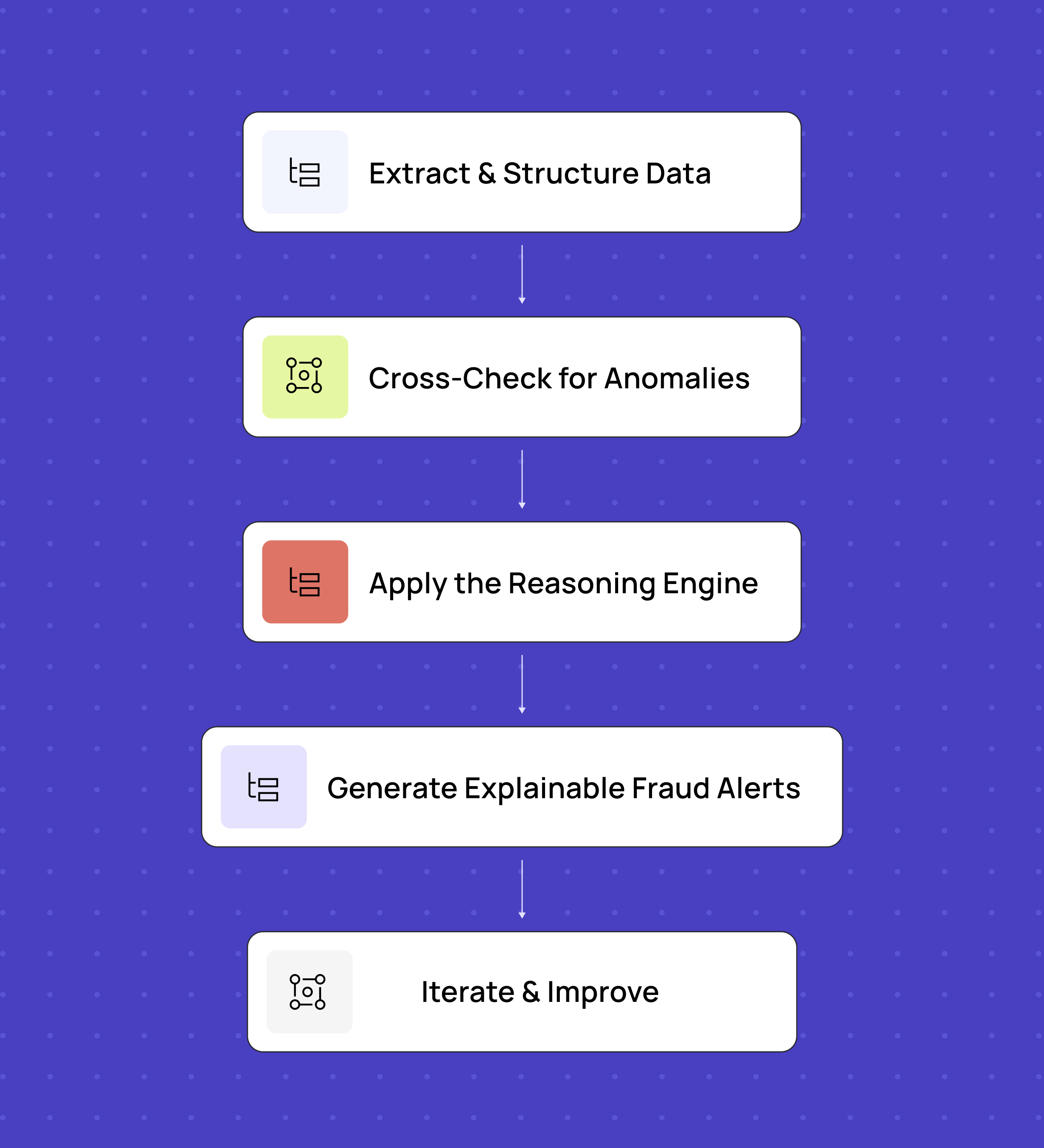
- Extraction et structuration des données – Notre OCR basé sur un modèle de langage de grande envergure (LLM) numérise les factures, les contrats et les e-mails, mais nous utilisons des instructions personnalisées pour chaque type de document afin de garantir la précision.
- Vérification croisée des anomalies: les données extraites sont comparées d'un document à l'autre afin d'identifier les incohérences au niveau des adresses, des prix, des descriptions de produits, etc.
- Utilisez le moteur de raisonnement: les grands modèles de langage (LLM) analysent les cas ambigus, mettent au jour des schémas cachés et fournissent des informations contextuelles, un peu comme un détective numérique qui rassemble des indices.
- Générer des alertes de fraude explicables: les modèles de langage de grande envergure (LLM) signalent les anomalies en fournissant des justifications claires, ce qui permet aux analystes de valider plus rapidement les risques réels.
- Itération et amélioration - La fraude évolue, et la détection doit en faire de même. Nous affinons en permanence les consignes et le réglage des modèles en nous appuyant sur les faux positifs et les faux négatifs.
Ce modèle hybride alliait automatisation et expertise humaine, permettant ainsi d'améliorer l'efficacité sans compromettre la précision.
5. La route à parcourir
L'avenir de l'IA dans la gestion des risques va au-delà des simples systèmes d'entrée-sortie basés sur les modèles de langage à grande échelle (LLM) pour s'orienter vers une automatisation intelligente fondée sur des agents.
Les récentes avancées en matière d’agents d’IA— des systèmes autonomes capables de raisonnement en plusieurs étapes et de recherche — permettront d’améliorer encore davantage la détection des fraudes et le respect des réglementations. Le nouvel agent de recherche approfondie d’OpenAI illustre parfaitement cette évolution, démontrant le potentiel des enquêtes menées par l’IA et des analyses approfondies.
Cependant, l'automatisation croissante comporte des risques. Les agents d'IA restent fragiles ; ceux qui ont travaillé avec eux savent qu'ils peuvent, un instant, fournir des analyses remarquables et, l'instant d'après, tourner en rond. Bien que les progrès soient rapides, il reste risqué de s'en remettre aveuglément à l'automatisation. Il sera essentiel de maintenir un équilibre entre l'automatisation et le jugement d'expert.
La formule gagnante: Utilisez des agents IA pour les analyses approfondies, mais exigez une validation humaine pour les actions à enjeux élevés (par exemple, le gel de comptes).
L'histoire des grands modèles de langage (LLM) dans la gestion des risques ne se résume pas à une simple question d'innovation : c'est avant tout une question d'équilibre. Comme nous l'avons vu, les LLM apportent de nouvelles capacités puissantes, permettant une analyse plus approfondie et une prise de décision plus rapide. Cependant, ils ne sont pas infaillibles. Leur efficacité dépend entièrement de la manière dont ils sont intégrés, régis et contrôlés au sein d'un cadre plus large de gestion des risques.
Points clés à retenir pour la mise en œuvre :
- Les modèles de langage de grande envergure (LLM) viennent compléter, sans toutefois remplacer, l'apprentissage automatique traditionnel. Utilisez-les pour traiter les données non structurées et les scénarios fortement dépendants du contexte, tout en conservant des modèles d'apprentissage automatique structurés pour une évaluation précise et quantifiable des risques.
- La gouvernance n'est pas négociable: même les meilleurs systèmes d'IA échouent s'ils ne font pas l'objet d'une surveillance et d'une mise en application rigoureuses. Veillez à mettre en place des protocoles clairs et des procédures d'escalade.
- La collaboration entre l'humain et l'IA est la formule gagnante: automatisez les tâches routinières, mais veillez à toujours faire appel au jugement humain pour les décisions à enjeux élevés.
- Une adaptation constante est essentielle: la fraude évolue, et les systèmes de détection doivent en faire de même. L'amélioration itérative, le développement rapide et le perfectionnement des processus sont indispensables.
Au final, les organisations qui réussiront seront celles qui considéreront les LLM pour ce qu’ils sont : de puissants alliés dans le travail d’enquête, et non des solutions miracles.
Avertissement
Les informations fournies dans cet article ne constituent pas et ne visent pas à constituer des conseils professionnels ; toutes les informations, tous les contenus et tous les documents sont fournis à titre informatif et éducatif uniquement. Par conséquent, avant de prendre toute mesure sur la base de ces informations, nous vous recommandons de consulter les professionnels compétents.
Foire aux questions (FAQ)
Q : Comment les modèles de langage de grande envergure (LLM) sont-ils utilisés dans la détection des fraudes dans le secteur de la fintech ?
R : Les grands modèles linguistiques (LLM) agissent comme des partenaires d'enquête : ils analysent les factures, les contrats et les données non structurées afin de signaler les anomalies que les systèmes traditionnels pourraient ne pas détecter. Ils permettent ainsi de réduire les vérifications manuelles et d'accélérer les enquêtes sur les fraudes.
Q : Quelle est la différence entre les modèles de langage de grande envergure (LLM) et l'apprentissage automatique traditionnel dans le domaine de la gestion des risques ?
R : Les modèles traditionnels d’apprentissage automatique sont particulièrement efficaces dans le contexte des données structurées, telles que les cotes de crédit et l’historique de remboursement. Les modèles de langage à grande échelle (LLM) excellent quant à eux dans les cas de fraude impliquant des données non structurées et fortement dépendantes du contexte, en aidant à détecter des schémas cachés dans les textes, les documents et les comportements. Ensemble, ils permettent de mettre en place des stratégies de détection de la fraude plus efficaces.
Q : Les modèles de langage de grande envergure (LLM) peuvent-ils améliorer les processus de conformité et de « KYB » ?
R : Oui. Les modèles de langage de grande envergure (LLM) permettent d'automatiser des tâches telles que le filtrage multilingue des sanctions et la vérification des immatriculations d'entreprises, ce qui réduit la charge de travail manuelle tout en améliorant la précision. Les enquêteurs humains continuent de traiter les zones d'ombre, mais les LLM peuvent accélérer considérablement les contrôles de conformité.
Q : Quels sont les avantages de l'utilisation des modèles de langage de grande envergure (LLM) pour la détection des fraudes dans les secteurs de la fintech et de la banque ?
R : Les modèles de langage de grande envergure (LLM) permettent de réduire les faux positifs, d’améliorer la détection des anomalies et de mettre au jour des réseaux de fraude cachés en analysant des incohérences subtiles. Cela se traduit par des enquêtes plus rapides sur les fraudes, moins de goulots d’étranglement en matière de conformité et une réduction des coûts opérationnels. Demandez une démonstration pour découvrir comment garder une longueur d’avance sur la fraude grâce à la plateforme décisionnelle IA de Taktile.
Q : Les modèles de langage de grande envergure (LLM) sont-ils en train de remplacer les enquêteurs spécialisés dans la lutte contre la fraude ?
R : Non. Les modèles de langage de grande envergure (LLM) doivent venir compléter l'expertise humaine, et non la remplacer. Ils peuvent prendre en charge les tâches de détection répétitives et fournir des analyses riches en contexte, tandis que les humains continuent de prendre la décision finale dans les cas de fraude et de non-conformité aux enjeux élevés.





