IA, Fraude 5 minutos de leitura
Como os LLMs estão se tornando parceiros de investigação na detecção de fraudes no setor de fintech


O rápido avanço da IA transformou setores em todos os âmbitos, mas poucas áreas sofreram um impacto tão drástico quanto a gestão de riscos no setor de fintech. Os Modelos de Linguagem de Grande Escala (LLMs) estão agora revolucionando a detecção de fraudes, a conformidade e a avaliação de risco de crédito, complementando as abordagens tradicionais de aprendizado de máquina (ML).
Com ampla experiência na liderança de IA e Ciência de Dados no setor de fintech, tenho conhecimento prático sobre a integração de ferramentas baseadas em IA nos processos de tomada de decisão e nos fluxos de trabalho de automação. No entanto, como veremos neste artigo, os LLMs não são soluções milagrosas. Embora possam identificar padrões e agilizar investigações, sua eficácia depende inteiramente dos sistemas que os regem. Sem uma governança rigorosa e uma aplicação estrita das normas, mesmo os modelos de IA mais avançados, assim como os investigadores humanos mais qualificados, ficam impotentes.
Este artigo analisa a diferença entre os LLMs e o aprendizado de máquina tradicional, seus papéis distintos em relação ao risco de crédito, conformidade e, especialmente, à detecção de fraudes — área que exploraremos em profundidade —, além do futuro em constante evolução da IA na gestão de riscos.
1. A divisão tradicional entre ML e LLM: uma perspectiva pragmática
Um equívoco comum no setor de fintech é a ideia de que os LLMs estão prestes a substituir o aprendizado de máquina tradicional na avaliação de riscos. Isso não é verdade.
O aprendizado de máquina (ML) continua sendo a espinha dorsal da modelagem de risco de crédito, pois se baseia em dados estruturados (principalmente tabulares) com resultados claros e definidos. As instituições financeiras possuem — ou podem adquirir — vastos conjuntos de dados históricos sobre comportamentos de pagamento, o que permite que modelos bem calibrados, como o CatBoost, forneçam pontuações de crédito precisas. Por exemplo, um modelo tradicional de ML pode utilizar mais de 50 características (por exemplo, métricas financeiras, histórico de pagamentos) para prever inadimplências com alta precisão.
A detecção de fraudes e a conformidade, no entanto, são, por natureza, mais ambíguas. Ao contrário do risco de crédito, onde existe uma referência objetiva na forma de histórico de pagamentos, a fraude no setor B2B muitas vezes carece de classificações definitivas e conjuntos de dados estruturados. É aí que os LLMs se destacam. Sua capacidade de processar textos não estruturados — como faturas, e-mails e artigos de notícias — permite que identifiquem padrões e inconsistências que, de outra forma, exigiriam a intuição humana.
Comparação: ML tradicional x LLMs

Exemplo: Um LLM sinalizou uma fatura de fornecedor em que o volume de remessa declarado de “algodão orgânico” excedia a capacidade de produção conhecida do fornecedor — uma discrepância invisível para modelos de ML estruturados.
2. Risco de crédito: os LLMs como auxiliares (por enquanto)
Embora modelos de aprendizado de máquina como o CatBoost continuem sendo a base das decisões de crédito, os modelos de linguagem de grande escala (LLMs) desempenham um papel de apoio. Suas principais contribuições foram a otimização de processos internos, como o atendimento a consultas de rotina por meio de chatbots que criamos, o que economizou tempo para as equipes de risco de crédito.
Uma exceção foi o financiamento baseado em receitas, área em que os LLMs se destacaram na classificação de transações. Ao categorizar as transações (por exemplo, distinguindo “receita de assinaturas” de “vendas pontuais”), eles aumentaram a visibilidade do fluxo de caixa. Essas categorizações não só aprimoraram a análise interna, como também aumentaram a precisão e a eficiência dos modelos de ML posteriores.
Conclusão principal: Os LLMs complementam — mas não substituem — o ML tradicional na área de risco de crédito. Atualmente, seu papel é enriquecer as entradas de dados, e não tomar decisões finais.
3. Conformidade: os LLMs automatizam o trabalho rotineiro, não o julgamento
No âmbito da conformidade transfronteiriça, os LLMs reduziram em 40% a carga de trabalho manual em tarefas como a verificação multilíngue de sanções e a análise de documentos regulatórios. Por exemplo, eles simplificaram os processos de “Conheça a sua empresa” (KYB) ao sinalizar discrepâncias nos registros de empresas (por exemplo, uma entidade chinesa que alega ter sede nos EUA sem um endereço válido).
No entanto, a intervenção humana continua sendo fundamental. Quando um LLM sinalizou a “XXX Technologies” como uma possível correspondência com o “XXX Group”, que estava na lista de sanções, os investigadores confirmaram que se tratava de um falso positivo causado pela sobreposição de convenções de nomenclatura.
Conclusão principal: Os LLMs reduzem o ruído, mas não conseguem lidar com as áreas cinzentas da regulamentação. Uma abordagem híbrida — automatizando as triagens iniciais e reservando o julgamento humano para os casos que exigem intervenção — alcança o melhor equilíbrio.
4. Detecção de fraudes: os LLMs representam uma revolução
A detecção de fraudes requer sistemas capazes de se adaptar a táticas em constante evolução e de identificar padrões ocultos na complexidade. Os sistemas tradicionais baseados em regras funcionam bem em cenários estáveis e previsíveis, mas muitas vezes se mostram insuficientes quando confrontados com esquemas de fraude novos ou sofisticados. Os LLMs, por outro lado, têm demonstrado grande valor em áreas onde a ambiguidade e o contexto são essenciais, pois possuem uma forma de raciocínio baseado no “bom senso”.
O ano de 2024 marcou um ponto de inflexão significativo nesse sentido. Os avanços nos modelos de raciocínio levaram ao desenvolvimento dos “mecanismos de raciocínio”. Popularizada por Andrew Ng, essa abordagem enfatiza o uso de LLMs para raciocinar sobre dados ambíguos, em vez de confiar neles para obter conhecimento factual, o que acarreta riscos de alucinação. Inspirados por isso, estruturamos as investigações de fraudes como tarefas de resolução de problemas orientadas pela lógica.
Ao mesmo tempo, criamos pipelines de OCR baseados em LLM que passaram de ser, em grande parte, pouco confiáveis — e que, na prática, não economizavam tempo, já que tudo precisava ser verificado novamente — para se tornarem ferramentas altamente precisas para extrair e estruturar dados. No financiamento de faturas, esses pipelines permitiram a digitalização automatizada de faturas, registros de transporte e contratos. De fato, conseguimos superar o desempenho de nossos fornecedores de OCR tradicionais graças a esses avanços nos modelos de base.
Como os LLMs impulsionam a detecção de fraudes
Para reforçar as medidas antifraude, implementamos os LLMs de duas maneiras principais:
- Ferramentas operacionais essenciais: digitalização de grandes volumes de faturas para detectar discrepâncias em endereços, preços, valores e descrições de produtos — economizando um esforço manual significativo e acelerando os tempos de processamento.
- Motores de raciocínio: esses modelos funcionam como detetives digitais, reunindo pistas de maneira muito semelhante à de Sherlock Holmes em uma investigação. Embora ainda estejam em fase experimental, os resultados têm sido extremamente promissores.
Um avanço notável ocorreu com a correspondência de entidades, uma área em que os LLMs se destacam. Nosso sistema anterior dependia da correspondência aproximada, uma abordagem frágil e sensível a diferenças no comprimento das sequências de caracteres, endereços com formatação ligeiramente diferente, etc. Por exemplo, ele não conseguia reconhecer que “LHR” e “London Heathrow” se referiam ao mesmo aeroporto. Os LLMs, por outro lado, compreendiam inerentemente a relação entre essas entidades devido ao seu amplo conhecimento contextual proveniente dos dados de treinamento. Isso nos permitiu melhorar as verificações de consistência dos dados e reduzir drasticamente os falsos positivos.
O impacto: ganhos em eficiência e precisão
O resultado? Reduzimos o tempo de detecção manual de fraudes em mais de 60%, diminuímos significativamente os falsos positivos e melhoramos a precisão da detecção de anomalias. As próximas versões se concentrarão em aprimorar a adaptabilidade e minimizar a necessidade de intervenção humana em casos de baixo risco.
Uma vantagem inesperada foi a capacidade dos LLMs de detectar inconsistências sutis que escapavam aos sistemas tradicionais e aos analistas. Por exemplo, eles descobriram uma rede de fraudes ao identificar erros gramaticais recorrentes em faturas de entidades supostamente não relacionadas. Embora os LLMs se destaquem na identificação dessas anomalias, os investigadores humanos continuam sendo essenciais para verificar e agir com base nessas descobertas.
Uma lição importante: Evite prompts genéricos. Os esquemas de fraude variam entre setores e regiões, exigindo fluxos de trabalho de IA personalizados. A melhor abordagem é iterativa, e os prompts devem ser refinados com base em falsos positivos e negativos.
Como garantir a eficácia da detecção de fraudes: lições da linha de frente
Depois de aperfeiçoar nossa abordagem de detecção de fraudes, chegamos a um fluxo de trabalho estruturado, mas flexível:
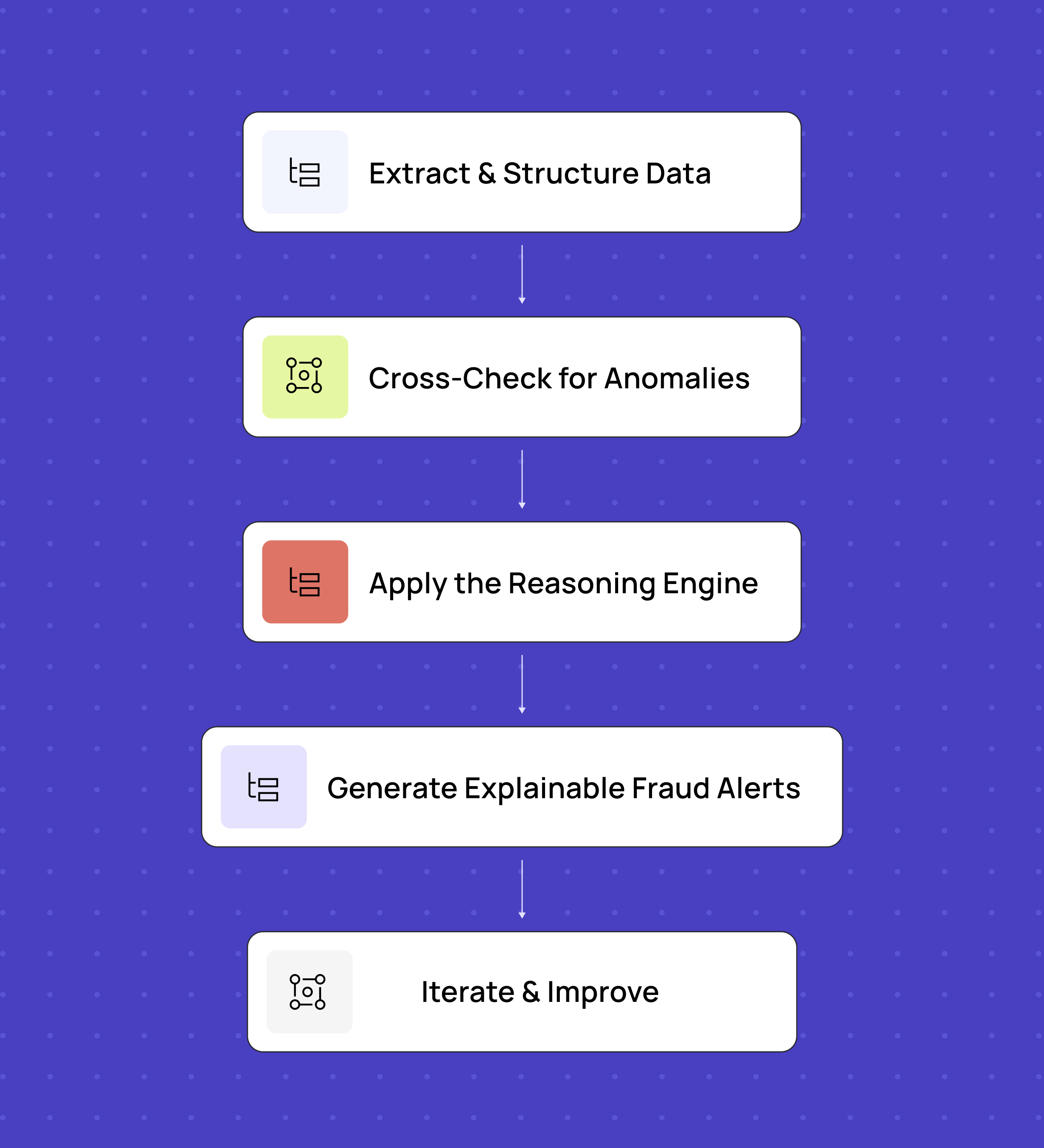
- Extração e organização de dados — O OCR baseado em LLM digitaliza faturas, contratos e e-mails, mas utilizamos instruções personalizadas para diferentes tipos de documentos a fim de garantir a precisão.
- Verificação cruzada de anomalias — Os dados extraídos são comparados entre os documentos, identificando inconsistências em endereços, preços, descrições de produtos, etc.
- Aplique o Mecanismo de Raciocínio — os LLMs analisam casos ambíguos, revelam padrões ocultos e fornecem insights contextuais, tal como um detetive digital que junta as pistas.
- Gerar alertas de fraude explicáveis — os modelos de linguagem de grande escala (LLMs) sinalizam anomalias com justificativas claras, permitindo que os analistas validem riscos reais com maior rapidez.
- Iterar e melhorar — A fraude evolui, e a detecção também precisa evoluir. Aperfeiçoamos continuamente as instruções e o ajuste dos modelos com base nos falsos positivos e nos falsos negativos.
Esse modelo híbrido combinou automação com a experiência humana, aumentando a eficiência sem comprometer a precisão.
5. O caminho à frente
O futuro da IA na gestão de riscos está evoluindo para além dos simples sistemas de entrada-saída baseados em LLM, rumo a uma automação inteligente e baseada em agentes.
Os recentes avanços em agentes de IA— sistemas autônomos capazes de raciocínio e pesquisa em várias etapas — irão aprimorar ainda mais a detecção de fraudes e a conformidade. O novo agente de pesquisa profunda da OpenAI exemplifica essa mudança, demonstrando o potencial das investigações e análises aprofundadas impulsionadas pela IA.
No entanto, o aumento da automação acarreta riscos. Os agentes de IA continuam sendo frágeis; quem já trabalhou com eles sabe que, num momento, podem gerar insights notáveis e, no momento seguinte, podem ficar dando voltas em círculos. Embora o progresso seja rápido, a confiança cega na automação continua sendo arriscada. Manter um equilíbrio entre a automação e o julgamento especializado será fundamental.
A fórmula vencedora: Use agentes de IA para análises aprofundadas, mas exija a aprovação humana para ações de alto risco (por exemplo, congelamento de contas).
A história dos LLMs na gestão de riscos não se resume apenas à inovação — trata-se de equilíbrio. Como vimos, os LLMs trazem novos recursos poderosos, permitindo análises mais aprofundadas e uma tomada de decisão mais rápida. No entanto, eles não são infalíveis. Sua eficácia depende inteiramente de como são integrados, regulamentados e monitorados dentro de uma estrutura mais ampla de gestão de riscos.
Pontos-chave para a implementação:
- Os LLMs aprimoram, mas não substituem, o aprendizado de máquina tradicional – Use-os para lidar com dados não estruturados e cenários com forte dependência de contexto, mas mantenha modelos de aprendizado de máquina estruturados para uma avaliação de risco precisa e quantificável.
- A governança não é negociável – mesmo os melhores sistemas de IA falham sem uma supervisão e uma aplicação rigorosas. Garanta a existência de protocolos claros e procedimentos de escalonamento.
- A colaboração entre humanos e IA é a fórmula vencedora – automatize as tarefas rotineiras, mas mantenha sempre o julgamento humano no processo para decisões de alto risco.
- A adaptação contínua é fundamental – a fraude evolui, e os sistemas de detecção também precisam evoluir. A melhoria iterativa, a engenharia ágil e o aperfeiçoamento dos fluxos de trabalho são essenciais.
No fim das contas, as organizações que terão sucesso serão aquelas que reconhecerem os LLMs pelo que eles realmente são: poderosos parceiros de investigação, e não soluções milagrosas.
Isenção de responsabilidade
As informações fornecidas neste artigo não constituem, nem têm a intenção de constituir, aconselhamento profissional; ao contrário, todas as informações, conteúdos e materiais têm apenas fins informativos e educacionais gerais. Assim, antes de tomar qualquer medida com base nessas informações, recomendamos que você consulte os profissionais adequados.
Perguntas frequentes (FAQs)
P: Como os LLMs são utilizados na detecção de fraudes no setor de fintech?
R: Os Modelos de Linguagem de Grande Escala (LLMs) atuam como parceiros de investigação: analisam faturas, contratos e dados não estruturados para identificar anomalias que os sistemas tradicionais poderiam deixar passar. Com isso, eles podem reduzir as revisões manuais e acelerar as investigações de fraudes.
P: Qual é a diferença entre os LLMs e o aprendizado de máquina tradicional na gestão de riscos?
R: Os modelos tradicionais de aprendizado de máquina se destacam no contexto de dados estruturados, como pontuações de crédito e histórico de pagamentos. Os LLMs se destacam em casos de fraude não estruturados e com forte componente contextual, ajudando a detectar padrões ocultos em textos, documentos e comportamentos. Juntos, eles criam estratégias mais eficazes de detecção de fraudes.
P: Os LLMs podem melhorar os processos de conformidade e de verificação de identidade do cliente (KYB)?
R: Sim. Os LLMs podem automatizar tarefas como a triagem multilíngue de sanções e a verificação de registros de empresas, reduzindo a carga de trabalho manual e, ao mesmo tempo, aumentando a precisão. Os investigadores humanos ainda lidam com as áreas cinzentas, mas os LLMs podem acelerar significativamente as verificações de conformidade.
P: Quais são as vantagens de usar LLMs para a detecção de fraudes no setor de fintech e bancário?
R: Os LLMs podem reduzir os falsos positivos, melhorar a detecção de anomalias e revelar redes de fraude ocultas por meio da análise de inconsistências sutis. Isso significa investigações de fraude mais rápidas, menos gargalos de conformidade e custos operacionais mais baixos. Solicite uma demonstração para ver como você pode se antecipar às fraudes com a Plataforma de Decisão por IA da Taktile.
P: Os LLMs estão substituindo os investigadores humanos especializados em fraudes?
R: Não. Os LLMs devem complementar, e não substituir, a expertise humana. Eles podem lidar com tarefas repetitivas de detecção e fornecer insights ricos em contexto, enquanto os seres humanos continuam a ter a palavra final em casos de fraude e conformidade de alto risco.





