IA, Datos 5 minutos de lectura
Los modelos de lenguaje grandes (LLM) tabulares ya están aquí, y traen consigo avances revolucionarios para los equipos de riesgo


Los avances en el aprendizaje profundo han impulsado innovaciones en casi todos los sectores, desde la movilidad (Waymo) y la biología (AlphaFold) hasta la música (Suno.ai). Sin embargo, a pesar del éxito del aprendizaje profundo en tareas altamente complejas, como los autos autónomos, las aplicaciones relacionadas con el riesgo han brillado por su ausencia en esta revolución. Pero esto está a punto de cambiar.
Una de las razones principales por las que los equipos de gestión de riesgos aún no han integrado las redes neuronales profundas en sus herramientas es su dificultad histórica con los datos tabulares. Los bancos, las empresas de tecnología financiera y las compañías de seguros cuentan con una gran cantidad de datos tabulares y los utilizan a diario para prevenir el fraude, detectar el lavado de dinero y determinar el riesgo crediticio. Y cuando se trata de desarrollar modelos de predicción de alta precisión para esos casos de uso, la familia de modelos de árboles potenciados por gradientes ha reinado sin rival.
El «momento ChatGPT» de los datos tabulares
En un lanzamiento que los expertos del sector han bautizado como el «momento ChatGPT» de los datos tabulares, Prior Labs presentó un modelo revolucionario: TabPFN. Este modelo supera ampliamente a los métodos existentes en conjuntos de datos tabulares en una amplia gama de tareas relacionadas con este tipo de datos, un hallazgo tan significativo que fue publicado recientemente en Nature.
Dada la amplia gama de aplicaciones de alto valor en el sector de los servicios financieros, nos entusiasma asociarnos con Prior Labs para brindar a los equipos de riesgo, fraude y cumplimiento normativo acceso a TabPFN.
Puntos clave
- Prior Labs ha lanzado un modelo revolucionario, TabPFN, que supera ampliamente a los métodos existentes en conjuntos de datos tabulares en una amplia gama de tareas relacionadas con tablas.
- Este modelo representa lo último en tecnología para entornos con pocos datos, y los equipos no necesitan un reentrenamiento complejo ni una infraestructura de MLOps.
- Nos hemos asociado con Prior Labs para que TabPFN esté disponible en la plataforma Taktile, con el fin de facilitar su uso en aplicaciones de gestión de riesgos y optimización de decisiones.
- El modelo ya está demostrando su utilidad en múltiples aplicaciones relacionadas con el riesgo, como los controles de fraude y la detección de anomalías en el riesgo crediticio.
Cómo funciona TabPFN
A diferencia de intentos anteriores por hacer que las redes neuronales profundas resulten útiles en entornos tabulares, este modelo está preentrenado. De manera similar a cómo los modelos de lenguaje grandes (LLM) modernos se preentrenan con un amplio corpus de datos de texto —que incluye la mayor parte de la información pública de Internet—, TabPFN se ha preentrenado con una amplia variedad de conjuntos de datos sintéticos, lo cual constituye una innovación clave del modelo.
Cuando realizas una predicción con TabPFN, le proporcionas una cantidad de filas etiquetadas de tus datos, además de las filas sin etiquetar. A continuación, el sistema completa las filas sin etiquetar con predicciones, de manera similar a como un modelo de lenguaje grande (LLM) utiliza los ejemplos de una solicitud para ayudarte con una consulta.
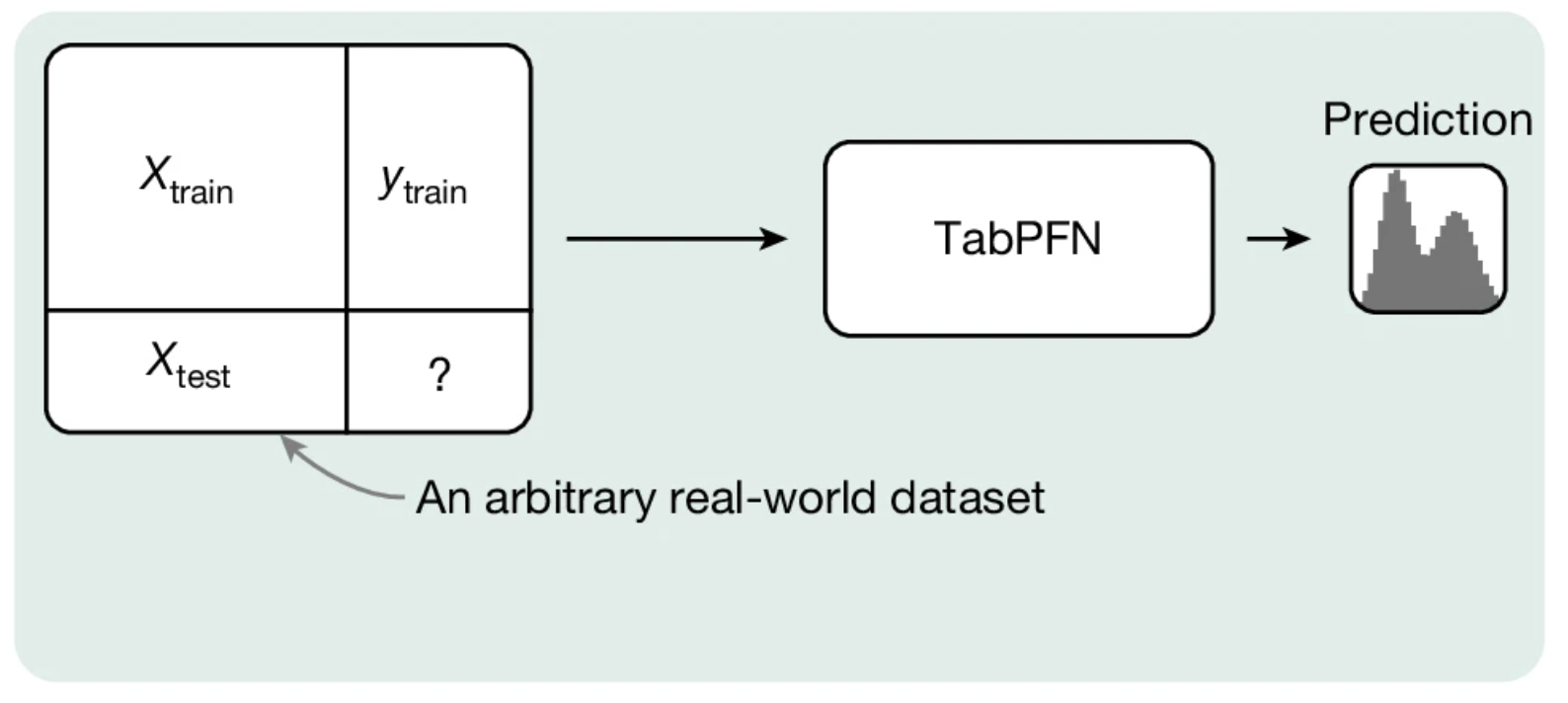
Cuando lo escuchas por primera vez, puede parecer increíble que no haya un entrenamiento del modelo en el sentido tradicional del término. Los parámetros (pesos) del modelo permanecen fijos durante todo el proceso. En cambio, el modelo se basa en la flexibilidad y el poder de la arquitectura del transformador para aprender los patrones de tus datos mientras realiza la predicción. El hecho de que esto funcione tan bien también fue una sorpresa en los inicios del modelado del lenguaje.
El valor de TabPFN para los profesionales del riesgo
Dado que el modelo no se entrena para cada nuevo caso de uso y se basa en gran medida en sus conocimientos previos del entrenamiento previo, existen algunas ventajas clave para los profesionales del sector de servicios financieros:
- Los expertos en la materia ahora pueden crear predicciones de modelos competitivas sin necesidad de contar con años de experiencia en ciencia de datos; esto se traduce en equipos más pequeños, más ágiles y con mayor autonomía.
- El modelo funciona bien en entornos con pocos datos, lo cual resulta especialmente interesante para aplicaciones relacionadas con el fraude, el crédito y la lucha contra el lavado de dinero, ya que muchas empresas cuentan con relativamente pocos verdaderos positivos.
- Los equipos no necesitan una infraestructura compleja de reentrenamiento y MLOps; al no haber reentrenamiento, se puede minimizar la carga administrativa derivada de la validación, las pruebas y la aprobación de los modelos.
TabPFN también incluye valiosas funciones adicionales que suelen ser una fuente de dificultades en el aprendizaje automático:
- El modelo devuelve, por supuesto, distribuciones para sus resultados, que puedes utilizar en las decisiones posteriores.
- El modelo maneja de forma nativa los valores faltantes y los valores atípicos, por lo que no es necesario que te preocupes por la imputación ni por otras estrategias para adaptar los datos al formato que espera tu modelo.
- El modelo puede ofrecer explicaciones sobre sus predicciones (utilizando los llamados «valores de Shapley»), lo que mitiga las preocupaciones en torno a la IA de «caja negra».
“Estamos muy entusiasmados con la capacidad de TabPFN para transformar la forma en que los equipos trabajan con el aprendizaje profundo para desarrollar y optimizar productos financieros. Los casos de uso que estamos viendo con Taktile son, en realidad, solo el comienzo de lo que se puede lograr.”
Aplicaciones prácticas de TabPFN en casos de uso relacionados con el riesgo
1. Verificaciones de fraude
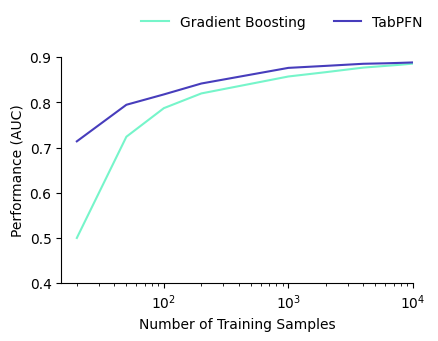
Dado que el modelo ofrece un buen desempeño en entornos con pocos datos, creemos que la aplicación inmediata más interesante son los controles de fraude. Hemos evaluado el desempeño del modelo en un conjunto de datos anónimo y real sobre fraudes en la apertura de cuentas y lo hemos comparado con un enfoque estándar de árboles potenciados. Cuanto más dispersos son los datos, mayor es el rendimiento superior del modelo frente al enfoque clásico de aprendizaje automático. Observe cómo el modelo funciona sorprendentemente bien cuando apenas cuenta con datos de entrenamiento: este es el poder del preentrenamiento en acción.
Ejemplo: Detección de fraudes al abrir una cuenta
2. Detección de anomalías en el riesgo crediticio
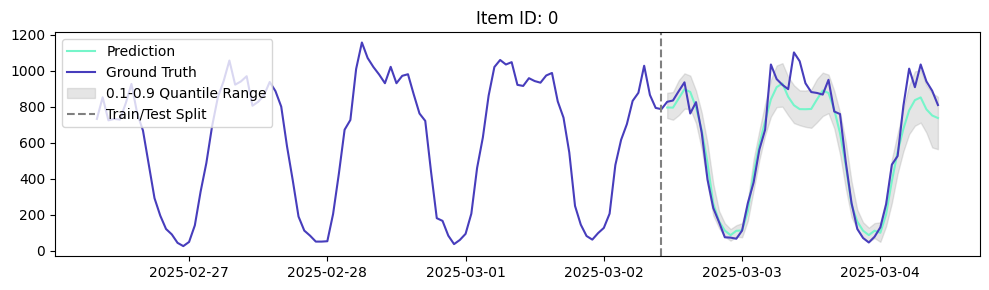
Otra aplicación que nos apasiona es la detección de anomalías. El modelo ocupa el primer lugar en entornos de series temporales, superando incluso a Chronos de Amazon, por lo que también se puede utilizar para pronosticar tasas de aprobación y métricas clave, como el número de solicitudes o la distribución de las calificaciones FICO de los solicitantes. Si las métricas observadas se desvían demasiado de esas distribuciones, puedes generar una alerta para que los analistas investiguen la anomalía.
Ejemplo: Detección de anomalías en las solicitudes diarias de préstamos
Estos son solo dos ejemplos de por qué nos entusiasma tanto TabPFN; creemos que hay innumerables casos de uso valiosos más.
Sigue siendo importante tener en cuenta las limitaciones. En la actualidad, el tiempo de predicción (latencia de inferencia) es relativamente alto y existen restricciones en cuanto al tamaño de los datos que se pueden procesar. Sin embargo, esperamos que ambas limitaciones se reduzcan rápidamente a lo largo de 2025.
¿Quieres saber cómo TabPFN podría aportar valor a tu caso de uso específico?
Lecturas adicionales recomendadas
- La IA aplicada al riesgo en acción: cómo los equipos de riesgo están desarrollando agentes de IA para generar un impacto en el mundo real
- Cómo los modelos de lenguaje grande (LLM) se están convirtiendo en socios de investigación en la detección de fraudes en el sector fintech
- De la calificación crediticia a la IA generativa: cómo ha evolucionado la toma de decisiones crediticias en la actualidad y qué nos depara el futuro
- IA sin exageraciones: cómo sacar verdadero provecho de los modelos de lenguaje grande (LLM) sin distraerse





