IA, Fraude 5 minutos de lectura
Cómo los modelos de lenguaje grande (LLM) se están convirtiendo en socios de investigación en la detección de fraudes en el sector fintech


El rápido avance de la inteligencia artificial (IA) ha transformado todos los sectores, pero pocas áreas han experimentado un impacto tan drástico como la gestión de riesgos en el sector fintech. Los modelos de lenguaje a gran escala (LLM) están revolucionando la detección de fraudes, el cumplimiento normativo y la evaluación del riesgo crediticio, complementando los enfoques tradicionales de aprendizaje automático (ML).
Gracias a mi amplia experiencia al frente de proyectos de IA y ciencia de datos en el sector fintech, cuento con conocimientos de primera mano sobre la integración de herramientas basadas en IA en los procesos de toma de decisiones y automatización. Sin embargo, como veremos en esta publicación, los modelos de lenguaje grande (LLM) no son soluciones mágicas. Si bien pueden descubrir patrones y agilizar las investigaciones, su eficacia depende directamente de los sistemas que los rigen. Sin una gobernanza rigurosa y una aplicación estricta de las normas, incluso los modelos de IA más avanzados, así como los investigadores humanos más capacitados, se ven impotentes.
En esta publicación se analiza la diferencia entre los modelos de lenguaje grande (LLM) y el aprendizaje automático tradicional, sus funciones específicas en el riesgo crediticio, el cumplimiento normativo y, sobre todo, la detección de fraudes —el área que exploraremos a fondo—, así como el futuro en constante evolución de la inteligencia artificial en la gestión de riesgos.
1. La división tradicional entre el aprendizaje automático (ML) y los modelos de lenguaje grande (LLM): una perspectiva pragmática
Una idea errónea muy común en el sector fintech es que los modelos de lenguaje grande (LLM) están destinados a reemplazar el aprendizaje automático tradicional en la evaluación de riesgos. Esto no es así.
El aprendizaje automático (ML) sigue siendo la columna vertebral de la modelación del riesgo crediticio porque se nutre de datos estructurados (en su mayoría tabulares) con resultados claros y definidos. Las entidades crediticias cuentan con —o pueden adquirir— amplios conjuntos de datos históricos sobre comportamientos de pago, lo que permite que modelos bien calibrados como CatBoost ofrezcan puntuaciones crediticias precisas. Por ejemplo, un modelo tradicional de aprendizaje automático podría utilizar más de 50 características (por ejemplo, métricas financieras, historial de pagos) para predecir incumplimientos con alta precisión.
La detección de fraudes y el cumplimiento normativo, sin embargo, son, por naturaleza, más ambiguos. A diferencia del riesgo crediticio, donde existe una «verdad de referencia» en forma de historial de pagos, el fraude B2B a menudo carece de etiquetas definitivas y de conjuntos de datos estructurados. Aquí es donde los LLM se destacan. Su capacidad para procesar texto no estructurado —como facturas, correos electrónicos y artículos de noticias— les permite descubrir patrones e inconsistencias que, de otra manera, requerirían la intuición humana.
Comparación: Aprendizaje automático tradicional frente a los modelos de lenguaje grandes (LLM)

Ejemplo: Un modelo de lenguaje grande (LLM) detectó una factura de un proveedor en la que el volumen de envío de «algodón orgánico» indicado superaba la capacidad de producción conocida del proveedor, una discrepancia que los modelos de aprendizaje automático estructurados no podían detectar.
2. Riesgo crediticio: los modelos de lenguaje grande (LLM) como compañeros (por ahora)
Si bien los modelos de aprendizaje automático (ML) como CatBoost siguen siendo la base de las decisiones crediticias, los modelos de lenguaje grande (LLM) desempeñan un papel de apoyo. Sus principales contribuciones consistieron en agilizar los procesos internos, como responder consultas de rutina a través de los chatbots que creamos, lo que permitió ahorrar tiempo a los equipos de riesgo crediticio.
Una excepción fue el financiamiento basado en ingresos, donde los LLM se destacaron en la clasificación de transacciones. Al categorizar las transacciones (por ejemplo, distinguiendo los «ingresos por suscripción» de las «ventas únicas»), mejoraron la visibilidad del flujo de efectivo. Estas categorizaciones no solo mejoraron el análisis interno, sino que también aumentaron la precisión y la eficiencia de los modelos de aprendizaje automático posteriores.
Conclusión clave: Los modelos de lenguaje grande (LLM) complementan —pero no reemplazan— el aprendizaje automático tradicional en el riesgo crediticio. Su función actual es enriquecer los datos de entrada, no tomar decisiones finales.
3. Cumplimiento: Los modelos de lenguaje grandes (LLM) automatizan el trabajo rutinario, no la toma de decisiones
En el ámbito del cumplimiento normativo transfronterizo, los modelos de lenguaje grande (LLM) han reducido la carga de trabajo manual en un 40 % en tareas como la verificación multilingüe de sanciones y el análisis de documentos normativos. Por ejemplo, han optimizado los procesos de «Conoce a tu empresa» (KYB) al señalar discrepancias en los registros de las empresas (por ejemplo, una entidad china que afirma tener su sede en EE. UU. sin una dirección válida).
Sin embargo, la intervención humana sigue siendo fundamental. Cuando un modelo de lenguaje grande (LLM) señaló a «XXX Technologies» como una posible coincidencia con el «Grupo XXX», sujeto a sanciones, los investigadores confirmaron que se trataba de un falso positivo causado por la coincidencia de convenciones de nomenclatura.
Conclusión clave: Los modelos de lenguaje grande (LLM) reducen el ruido, pero no pueden lidiar con las zonas grises normativas. Un enfoque híbrido —que automatice las evaluaciones iniciales y reserve el juicio humano para los casos que requieran atención especial— ofrece el mejor equilibrio.
4. Detección de fraudes: los modelos de lenguaje grande (LLM) marcan un antes y un después
La detección de fraudes requiere sistemas capaces de adaptarse a tácticas en constante evolución y de descubrir patrones ocultos en la complejidad. Los sistemas tradicionales basados en reglas funcionan bien en escenarios estables y predecibles, pero a menudo se quedan cortos cuando se enfrentan a esquemas de fraude novedosos o sofisticados. Los modelos de lenguaje grande (LLM), por el contrario, han demostrado ser de gran valor en áreas donde la ambigüedad y el contexto son esenciales, ya que poseen una forma de razonamiento basado en el «sentido común».
El año 2024 marcó un punto de inflexión significativo en este sentido. Los avances en los modelos de razonamiento llevaron al desarrollo de los «motores de razonamiento». Popularizado por Andrew Ng, este enfoque hace hincapié en aprovechar los modelos de lenguaje grande (LLM) para razonar sobre datos ambiguos, en lugar de depender de ellos para obtener conocimiento factual, lo cual conlleva riesgos de alucinaciones. Inspirados por esto, estructuramos las investigaciones de fraude como tareas de resolución de problemas basadas en la lógica.
Al mismo tiempo, creamos flujos de trabajo de OCR impulsados por modelos de lenguaje grande (LLM) que pasaron de ser en gran medida poco confiables —y que, en la práctica, no representaban un ahorro de tiempo porque todo tenía que revisarse dos veces como resultado— a convertirse en herramientas de alta precisión para extraer y estructurar datos. En el financiamiento de facturas, estos flujos de trabajo permitieron el escaneo automatizado de facturas, registros de transporte y contratos. De hecho, pudimos superar a nuestros proveedores de OCR tradicionales gracias a estos avances en los modelos base.
Cómo los modelos de lenguaje grande (LLM) impulsan la detección de fraudes
Para reforzar las medidas contra el fraude, implementamos los modelos de lenguaje grande (LLM) de dos maneras principales:
- Herramientas operativas imprescindibles: escanean grandes volúmenes de facturas para detectar discrepancias en direcciones, precios, montos y descripciones de productos, lo que ahorra un esfuerzo manual considerable y acelera los tiempos de procesamiento.
- Motores de razonamiento: Estos modelos funcionan como detectives digitales, reuniendo pistas de manera muy similar a como lo hace Sherlock Holmes en una investigación. Aunque aún se encuentran en fase experimental, los resultados han sido sumamente prometedores.
Un avance notable se produjo con la correspondencia de entidades, un área en la que los modelos de lenguaje grande (LLM) se destacan. Nuestro sistema anterior se basaba en la coincidencia aproximada, un enfoque frágil y sensible a las diferencias en la longitud de las cadenas de caracteres, a direcciones con un formato ligeramente diferente, etc. Por ejemplo, no reconocía que «LHR» y «London Heathrow» se referían al mismo aeropuerto. Los LLM, por otro lado, entendían de manera inherente la relación entre estas entidades gracias a su amplio conocimiento contextual derivado de los datos de entrenamiento. Esto nos permitió mejorar las verificaciones de consistencia de los datos y reducir drásticamente los falsos positivos.
El impacto: mayores niveles de eficiencia y precisión
¿El resultado? Redujimos el tiempo dedicado a la detección manual de fraudes en más del 60 %, disminuimos significativamente los falsos positivos y mejoramos la precisión en la detección de anomalías. Las próximas versiones se centrarán en perfeccionar la adaptabilidad y minimizar la necesidad de intervención humana en los casos de bajo riesgo.
Una ventaja inesperada fue la capacidad de los modelos de lenguaje grande (LLM) para detectar inconsistencias sutiles que los sistemas y analistas tradicionales pasaban por alto. Por ejemplo, descubrieron una red de fraude al identificar errores gramaticales recurrentes en facturas de entidades que, en teoría, no tenían relación entre sí. Si bien los LLM se destacan por señalar este tipo de anomalías, los investigadores humanos siguen siendo fundamentales para verificar esta información y tomar medidas al respecto.
Una lección clave: Evita las indicaciones genéricas. Las estafas varían según el sector y la región, lo que requiere flujos de trabajo de IA personalizados. El mejor enfoque es iterativo, y las indicaciones deben perfeccionarse en función de los falsos positivos y negativos.
Cómo lograr que la detección de fraudes funcione: lecciones desde la primera línea
Tras perfeccionar nuestro enfoque de detección de fraudes, llegamos a un flujo de trabajo estructurado pero flexible:
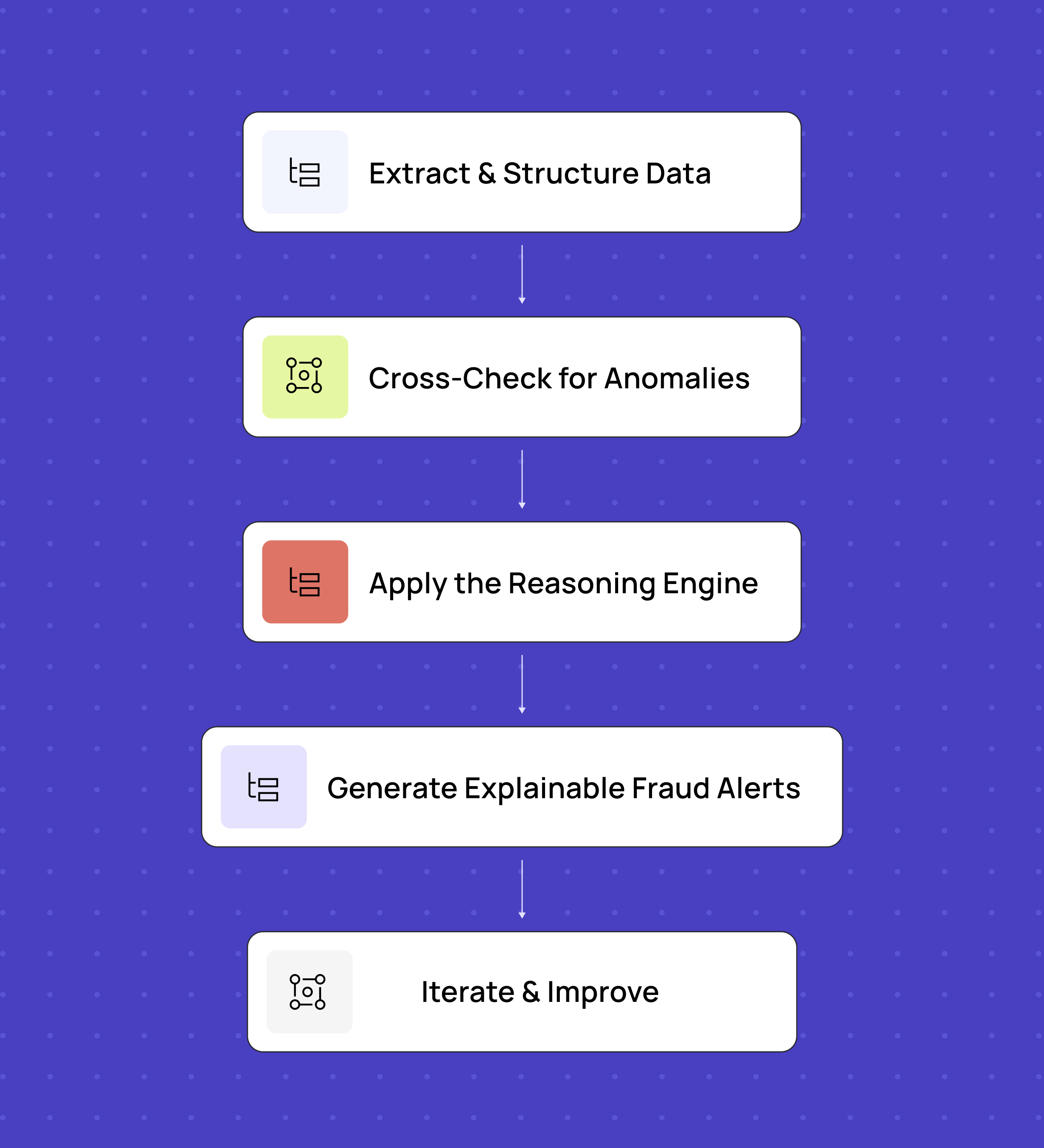
- Extracción y estructuración de datos: el OCR basado en modelos de lenguaje grande (LLM) digitaliza facturas, contratos y correos electrónicos, pero utilizamos indicaciones personalizadas para cada tipo de documento a fin de garantizar la precisión.
- Verificación cruzada de anomalías: los datos extraídos se comparan entre los distintos documentos para identificar inconsistencias en direcciones, precios, descripciones de productos, etc.
- Aplica el motor de razonamiento: los modelos de lenguaje grande (LLM) analizan casos ambiguos, descubren patrones ocultos y ofrecen información contextual, de manera muy similar a como lo haría un detective digital al armar el rompecabezas de las pistas.
- Generar alertas de fraude explicables: los modelos de lenguaje grande (LLM) señalan anomalías con justificaciones claras, lo que permite a los analistas validar los riesgos reales con mayor rapidez.
- Iterar y mejorar: el fraude evoluciona, y la detección también debe hacerlo. Refinamos continuamente las indicaciones y el ajuste de los modelos basándonos en los falsos positivos y los falsos negativos.
Este modelo híbrido combinó la automatización con la experiencia humana, lo que permitió mejorar la eficiencia sin comprometer la precisión.
5. El camino por delante
El futuro de la IA en la gestión de riesgos está evolucionando más allá de los simples sistemas de entrada-salida basados en modelos de lenguaje grande (LLM) hacia una automatización inteligente basada en agentes.
Los avances recientes en los agentes de IA—sistemas autónomos capaces de realizar razonamientos y búsquedas en múltiples pasos— mejorarán aún más la detección de fraudes y el cumplimiento normativo. El nuevo agente de investigación profunda de OpenAI ejemplifica este cambio, demostrando el potencial de las investigaciones impulsadas por IA y los análisis en profundidad.
Sin embargo, una mayor automatización conlleva riesgos. Los agentes de IA siguen siendo frágiles; quienes han trabajado con ellos saben que pueden generar ideas extraordinarias en un momento y, al siguiente, dar vueltas en círculos. Si bien el progreso es rápido, confiar ciegamente en la automatización sigue siendo arriesgado. Será fundamental mantener un equilibrio entre la automatización y el criterio de los expertos.
La fórmula ganadora: Utiliza agentes de IA para análisis en profundidad, pero exige la aprobación humana en acciones de alto riesgo (por ejemplo, la congelación de cuentas).
La historia de los modelos de lenguaje grande (LLM) en la gestión de riesgos no se trata solo de innovación, sino también de equilibrio. Como hemos visto, los LLM aportan nuevas y poderosas capacidades que permiten obtener una visión más profunda y tomar decisiones más rápidamente. Sin embargo, no son infalibles. Su efectividad depende por completo de cómo se integren, se regulen y se supervisen dentro de un marco más amplio de gestión de riesgos.
Puntos clave para la implementación:
- Los modelos de lenguaje grande (LLM) mejoran el aprendizaje automático tradicional, pero no lo reemplazan: utilícelos para manejar datos no estructurados y situaciones en las que el contexto es fundamental, pero mantenga los modelos de aprendizaje automático estructurados para una evaluación de riesgos precisa y cuantificable.
- La gobernanza no es negociable: incluso los mejores sistemas de IA fallan si no cuentan con una supervisión y un cumplimiento rigurosos. Asegúrate de contar con protocolos claros y procedimientos de escalamiento.
- La colaboración entre humanos e IA es la fórmula ganadora: automatiza las tareas rutinarias, pero mantén siempre el criterio humano en el proceso cuando se trate de decisiones de alto riesgo.
- La adaptación continua es clave: el fraude evoluciona y los sistemas de detección también deben hacerlo. La mejora iterativa, la ingeniería ágil y el perfeccionamiento de los flujos de trabajo son esenciales.
Al final, las organizaciones que tengan éxito serán aquellas que reconozcan a los modelos de lenguaje grande (LLM) por lo que son: poderosos aliados en la investigación, no soluciones mágicas.
Descargo de responsabilidad
La información proporcionada en este artículo no constituye ni pretende constituir asesoramiento profesional; por el contrario, toda la información, el contenido y el material se ofrecen únicamente con fines informativos y educativos generales. Por lo tanto, antes de tomar cualquier medida basada en dicha información, le recomendamos que consulte con los profesionales adecuados.
Preguntas frecuentes (FAQ)
P: ¿Cómo se utilizan los modelos de lenguaje grande (LLM) en la detección de fraudes en el sector fintech?
R: Los modelos de lenguaje a gran escala (LLM) actúan como socios de investigación: analizan facturas, contratos y datos no estructurados para detectar anomalías que los sistemas tradicionales podrían pasar por alto. Como resultado, pueden reducir las revisiones manuales y acelerar las investigaciones de fraude.
P: ¿Cuál es la diferencia entre los modelos de lenguaje grande (LLM) y el aprendizaje automático tradicional en la gestión de riesgos?
R: Los modelos tradicionales de aprendizaje automático se destacan en el contexto de datos estructurados, como las calificaciones crediticias y el historial de pagos. Los modelos de lenguaje grande (LLM) se destacan en casos de fraude no estructurados y con mucho contexto, ya que ayudan a detectar patrones ocultos en textos, documentos y comportamientos. Juntos, crean estrategias más sólidas para la detección de fraudes.
P: ¿Pueden los modelos de lenguaje grande (LLM) mejorar los procesos de cumplimiento normativo y de «Conoce a tu cliente» (KYB)?
R: Sí. Los modelos de lenguaje grande (LLM) pueden automatizar tareas como la verificación multilingüe de sanciones y la comprobación de registros mercantiles, lo que reduce la carga de trabajo manual y mejora la precisión. Los investigadores humanos siguen encargándose de los casos dudosos, pero los LLM pueden acelerar significativamente las verificaciones de cumplimiento.
P: ¿Cuáles son los beneficios de utilizar los modelos de lenguaje grande (LLM) para la detección de fraudes en el sector fintech y bancario?
R: Los modelos de lenguaje grande (LLM) pueden reducir los falsos positivos, mejorar la detección de anomalías y descubrir redes de fraude ocultas mediante el análisis de inconsistencias sutiles. Esto se traduce en investigaciones de fraude más rápidas, menos obstáculos en materia de cumplimiento normativo y menores costos operativos. Solicita una demostración para ver cómo puedes adelantarte al fraude con la Plataforma de Decisiones con IA de Taktile.
P: ¿Están los modelos de lenguaje grande (LLM) reemplazando a los investigadores humanos especializados en fraudes?
R: No. Los modelos de lenguaje grande (LLM) deben complementar, no sustituir, la experiencia humana. Pueden encargarse de tareas repetitivas de detección y ofrecer información rica en contexto, mientras que los seres humanos siguen siendo quienes toman la decisión final en casos de fraude y cumplimiento normativo de alto riesgo.





