AI, Fraud 5 min read
How LLMs are becoming investigative partners in fintech fraud detection


The rapid advancement of AI has transformed industries across the board, but few areas have seen as dramatic an impact as risk management in fintech. Large Language Models (LLMs) are now reshaping fraud detection, compliance, and credit risk assessment, augmenting traditional machine learning (ML) approaches.
With extensive experience leading AI and Data Science in fintech, I have firsthand knowledge of integrating AI-driven tools into decision-making and automation workflows. However, as we’ll see in this post, LLMs are not magic bullets. While they can unearth patterns and streamline investigations, they are only as effective as the systems governing them. Without rigorous governance and strict enforcement, even the most advanced AI models, as well as the most skilled human investigators, are powerless.
This post examines the divide between LLMs and traditional ML, their distinct roles in credit risk, compliance, and especially fraud detection—the area we will explore in depth—along with the evolving future of AI in risk management.
1. The traditional ML vs. LLM divide: A pragmatic perspective
A common misconception in fintech is that LLMs are set to replace traditional ML in risk assessment. This isn't the case.
ML remains the backbone of credit risk modeling because it thrives on structured (mostly tabular) data with clear, close-ended outcomes. Lenders have—or can buy—vast historical datasets on repayment behaviors, allowing for well-calibrated models like CatBoost to deliver accurate credit scoring. For example, a traditional ML model might use 50+ features (e.g., financial metrics, payment history) to predict defaults with high precision.
Fraud detection and compliance, however, are inherently more ambiguous. Unlike credit risk, where ground truth exists in the form of repayment history, B2B fraud often lacks definitive labels and structured datasets. This is where LLMs shine. Their ability to process unstructured text—such as invoices, emails, and news articles—enables them to uncover patterns and inconsistencies that would otherwise require human intuition.
Comparison: Traditional ML vs LLMs

Example: An LLM flagged a supplier invoice where the stated "organic cotton" shipment volume exceeded the supplier’s known production capacity—a mismatch invisible to structured ML models.
2. Credit Risk: LLMs as sidekicks (for now)
While ML models like CatBoost remain the foundation of credit decisions, LLMs play a supporting role. Their primary contributions were to streamline internal processes, like answering routine queries via chatbots we created, which saved time for credit risk teams.
An exception was revenue-based financing, where LLMs excelled in transaction labeling. By categorizing transactions (e.g., distinguishing "subscription revenue" from "one-time sales"), they improved cash flow visibility. These categorizations not only improved internal analysis but also enhanced the accuracy and efficiency of downstream ML models.
Key Insight: LLMs augment—but don’t replace—traditional ML in credit risk. Their role today is to enrich data inputs, not make final decisions.
3. Compliance: LLMs automate the grunt work, not the judgment
In cross-border compliance, LLMs have slashed manual workloads by 40% in tasks like multilingual sanction screenings and regulatory document analysis. For instance, they streamlined Know Your Business (KYB) processes by flagging discrepancies in company registrations (e.g., a Chinese entity claiming a U.S. headquarters without a valid address).
However, human intervention remains critical. When an LLM flagged "XXX Technologies" as a potential match for a sanctioned "XXX Group," investigators confirmed it was a false positive caused by overlapping naming conventions.
Key Takeaway: LLMs reduce noise but can’t navigate regulatory gray areas. A hybrid approach—automating initial screenings while reserving human judgment for escalations—strikes the best balance.
4. Fraud detection: LLMs are a game changer
Fraud detection requires systems that can adapt to evolving tactics and uncover patterns hidden in complexity. Traditional rules-based systems work well in stable, predictable scenarios but often fall short when faced with novel or sophisticated fraud schemes. LLMs, by contrast, have shown significant value in areas where ambiguity and context are essential because they possess a form of "common sense" reasoning.
The year 2024 marked a significant turning point in this regard. Advancements in reasoning models led to the development of "reasoning engines." Popularized by Andrew Ng, this approach emphasizes leveraging LLMs for reasoning over ambiguous data rather than relying on them for factual knowledge, which carries risks of hallucination. Inspired by this, we structured fraud investigations as logic-driven problem-solving tasks.
At the same time, we created LLM-powered OCR pipelines that transitioned from being largely unreliable—and effectively not really saving time because everything was double-checked as a result—to highly accurate tools for extracting and structuring data. In invoice financing, these pipelines enabled automated scanning of invoices, transportation records, and contracts. In fact, we were able to outperform our legacy OCR vendors due to these advancements in the foundation models.
How LLMs drive fraud detection
To enhance anti-fraud measures, we deployed LLMs in two primary ways:
- Operational workhorses: Scanning large volumes of invoices to detect mismatches in addresses, prices, amounts, and product descriptions—saving significant manual effort and accelerating processing times.
- Reasoning engines: These models function as digital detectives, piecing together clues much like Sherlock Holmes in an investigation. Though still experimental, the results have been extremely promising.
A notable breakthrough came with entity matching, an area where LLMs excel. Our previous system relied on fuzzy matching, a brittle approach sensitive to string length differences, slightly differently formatted addresses, etc. For example, it would fail to recognize that "LHR" and "London Heathrow" refer to the same airport. LLMs, on the other hand, inherently understood the relationship between these entities because of their broad contextual knowledge from training data. This allowed us to improve data consistency checks and dramatically reduce false positives.
The impact: Efficiency and accuracy gains
The result? We cut manual fraud detection time by over 60%, significantly reduced false positives, and improved anomaly detection accuracy. Future iterations would focus on refining adaptability and minimising the need for human intervention in low-risk cases.
One unexpected advantage was LLMs’ ability to detect subtle inconsistencies missed by traditional systems and analysts. For example, they uncovered a fraud ring by identifying recurring grammatical errors across invoices from supposedly unrelated entities. While LLMs excel at flagging such anomalies, human investigators remain crucial in verifying and acting on these insights.
A key learning: Avoid generic prompts. Fraud schemes vary across industries and geographies, requiring tailored AI workflows. The best approach is iterative, and prompts should be refined on false positives and negatives.
Making fraud detection work: Lessons from the front lines
After refining our fraud detection approach, we landed on a structured but flexible workflow:
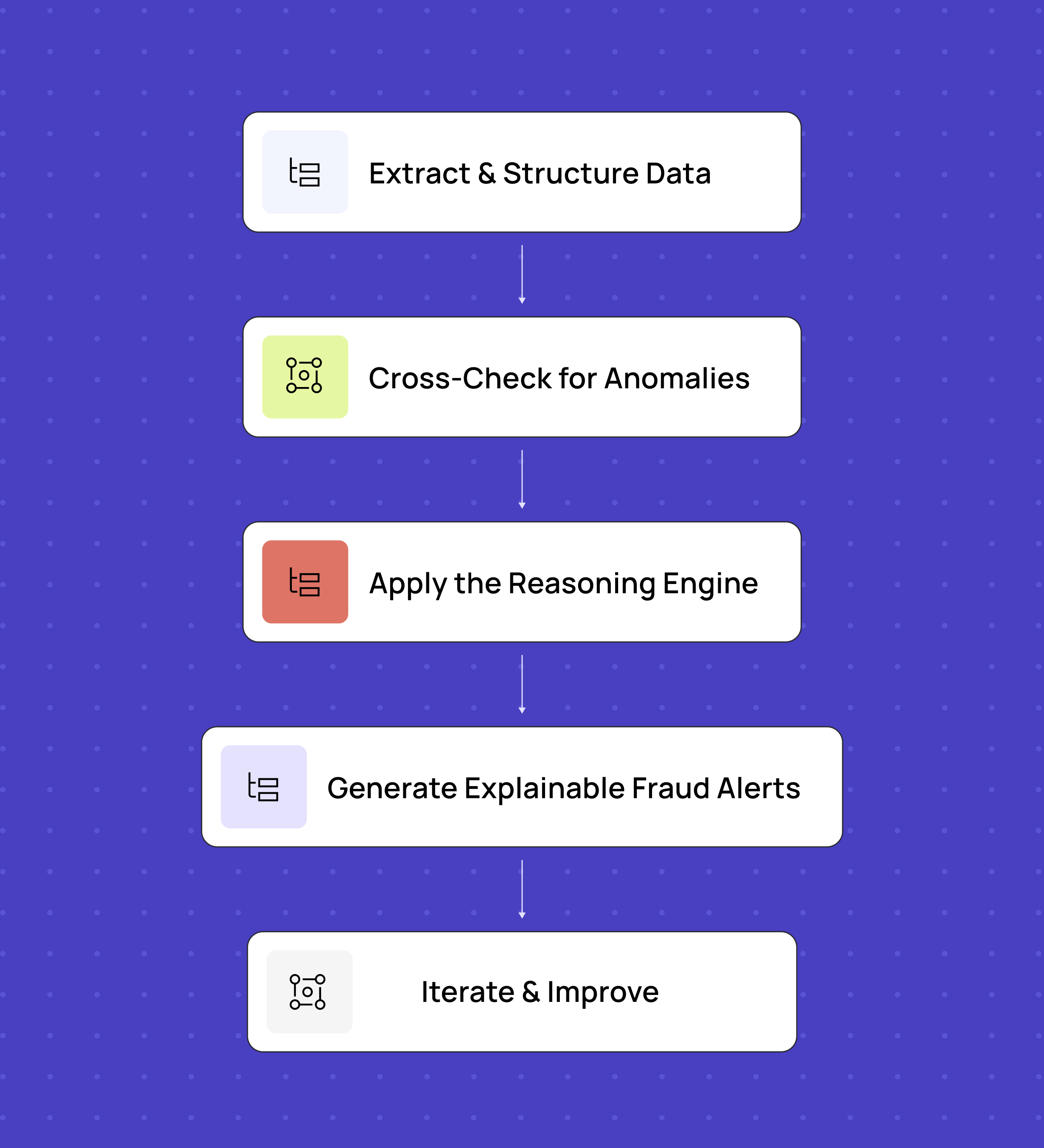
- Extract & Structure Data - LLM-powered OCR digitizes invoices, contracts, and emails, but we use customized prompts for different document types to ensure accuracy.
- Cross-Check for Anomalies - Extracted data is compared across documents, identifying inconsistencies in addresses, pricing, product descriptions, etc.
- Apply the Reasoning Engine - LLMs analyze ambiguous cases, uncover hidden patterns, and provide contextual insights, much like a digital detective piecing together clues.
- Generate Explainable Fraud Alerts - LLMs flag anomalies with clear justifications, making it faster for analysts to validate real risks.
- Iterate & Improve - Fraud evolves, and so must detection. We continuously refine prompts and model tuning based on false positives and false negatives.
This hybrid model balanced automation with human expertise, improving efficiency without compromising accuracy.
5. The road ahead
The future of AI in risk management is shifting beyond simple LLM-driven input-output systems toward intelligent, agent-based automation.
Recent advances in AI agents—autonomous systems capable of multi-step reasoning and research—will further enhance fraud detection and compliance. OpenAI’s new deep research agent exemplifies this shift, demonstrating the potential of AI-driven investigation and deep dives.
However, increased automation carries risks. AI agents remain fragile; those who have worked with them know they can produce remarkable insights one moment and chase their own tail the next. While progress is rapid, blind reliance on automation remains risky. Maintaining a balance between automation and expert judgment will be key.
The Winning Formula: Use AI agents for deep dives but require human sign-off on high-stakes actions (e.g., freezing accounts).
The story of LLMs in risk management is not just about innovation—it’s about balance. As we’ve seen, LLMs bring powerful new capabilities, enabling deeper insights and faster decision-making. Yet, they are not infallible. Their effectiveness depends entirely on how they are integrated, governed, and monitored within a broader risk management framework.
Key takeaways for implementation:
- LLMs enhance, but don’t replace, traditional ML – Use them to handle unstructured data and context-heavy scenarios, but maintain structured ML models for precise, quantifiable risk assessment.
- Governance is non-negotiable – Even the best AI systems fail without strong oversight and enforcement. Ensure clear protocols and escalation procedures.
- Human-AI collaboration is the winning formula – Automate routine tasks, but always keep human judgment in the loop for high-stakes decisions.
- Continuous adaptation is key – Fraud evolves, and so must detection systems. Iterative improvement, prompt engineering, and workflow refinement are essential.
In the end, the organizations that succeed will be those that recognize LLMs for what they are: powerful investigative partners, not magic bullets.
Disclaimer
This information provided in this article does not, and is not intended to constitute professional advice; instead, all information, content, and material are for general informational and educational purposes only. Accordingly, before taking any actions based upon such information, we encourage you to consult with the appropriate professionals.
Frequently Asked Questions (FAQs)
Q: How are LLMs used in fintech fraud detection?
A: Large Language Models (LLMs) act like investigative partners: scanning invoices, contracts, and unstructured data to flag anomalies that traditional systems might miss. As a result, they can reduce manual reviews and accelerate fraud investigations.
Q: What’s the difference between LLMs and traditional ML in risk management?
A: Traditional machine learning models excel in the context of structured data, such as credit scores and repayment history. LLMs shine in unstructured, context-heavy fraud cases, helping to detect hidden patterns across text, documents, and behaviors. Together, they create stronger fraud detection strategies.
Q: Can LLMs improve compliance and KYB processes?
A: Yes. LLMs can automate tasks like multilingual sanction screening and company registration checks, cutting manual workload while improving accuracy. Human investigators still handle gray areas, but LLMS can significantly speed up compliance checks.
Q: What are the benefits of using LLMs for fraud detection in fintech and banking?
A: LLMs can reduce false positives, improve anomaly detection, and uncover hidden fraud rings by analyzing subtle inconsistencies. This means faster fraud investigations, fewer compliance bottlenecks, and lower operational costs. Request a demo to see how you can stay ahead of fraud with Taktile’s AI Decision Platform.
Q: Are LLMs replacing human fraud investigators?
A: No. LLMs should augment, not replace, human expertise. They can handle repetitive detection tasks and provide context-rich insights, while humans remain the final judgment on high-stakes fraud and compliance cases.





